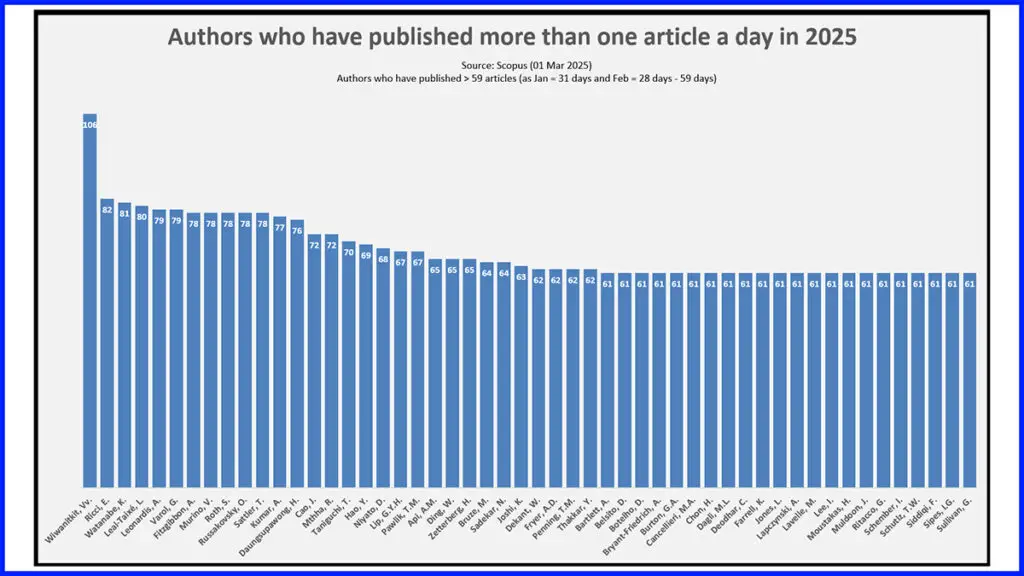
Hyper-prolific authors in Jan & Feb 2025
We looked at how many authors have published more than one paper in day in the first two months of 2025
We looked at how many authors have published more than one paper in day in the first two months of 2025

We ask why somebody would publish more than one letter a day in scientific journals and what workflow this would entail.
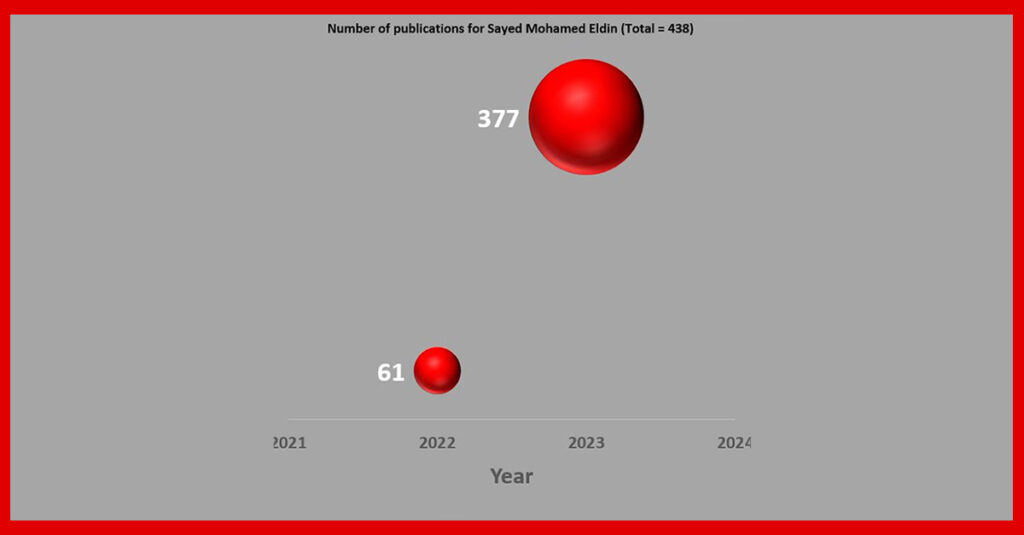
We look at the number of papers published by Sayed Mohamed Eldin published in 2022-2024. Prior to 2022, we cannot find any publications.

We look at an article that appears to cite a high number of papers from a journal that is difficult to tracks down and it also cites a high number of papers authored by the EiC of that journal.
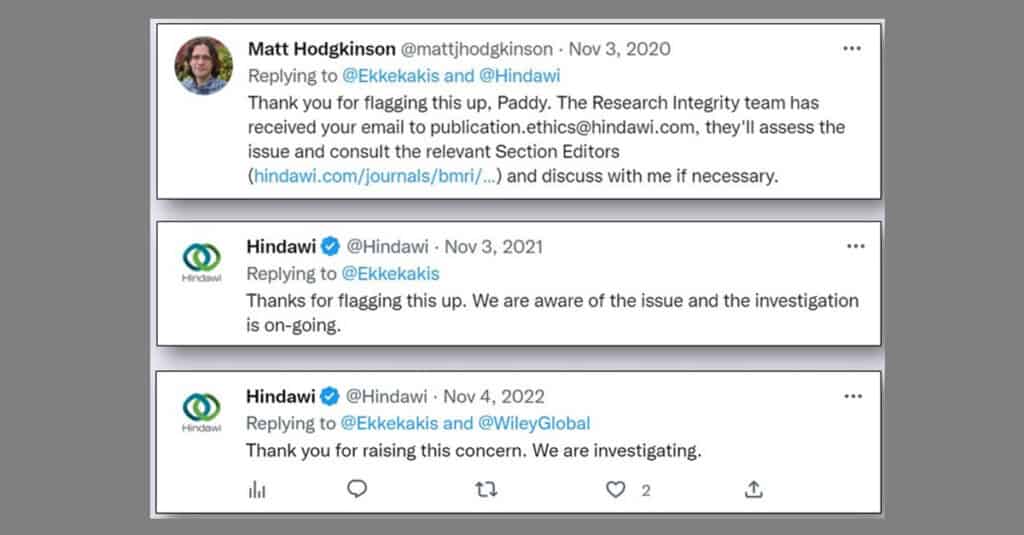
Ethical concerns were raised about three years ago, saying that a paper contained fake meta-analysis. The publisher says that it is still under investigation. We give our thoughts.
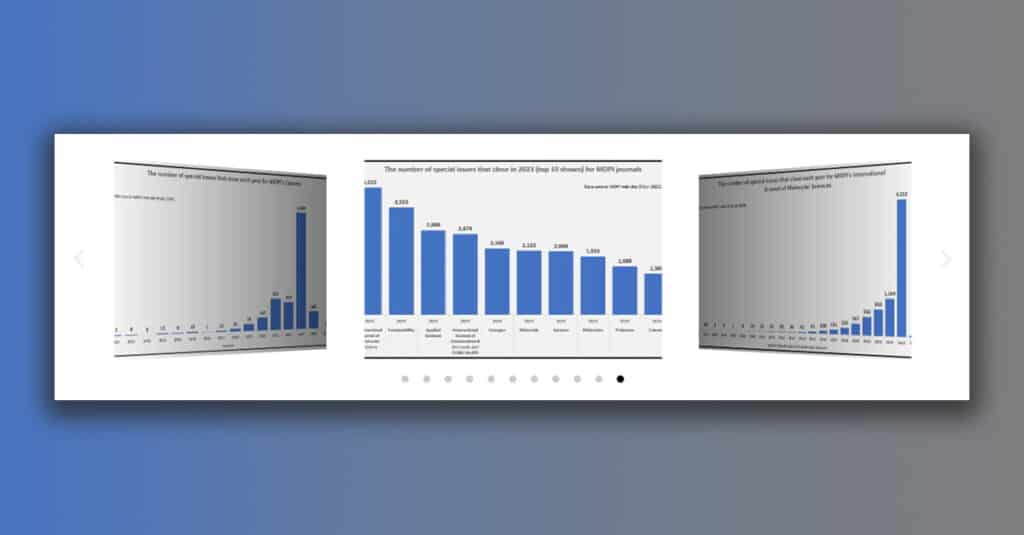
We look at how many special issues MDPI publishes, noting that the number has risen significantly in 2023.

This article is an update to our previous article, following some discussion on Twitter.

We noticed that many of Frontiers Media journals have thousands of editors. We explore the number of articles and editors they have, as well as the role of reviewers.

About a year ago we saw an email that said a journal had 10 articles already, but needed another 20 more. We have a look at this request, now that a year has passed.
We have been tweeting about Opast Publishing Group. In this article we summarize our findings.