In a recent X (tweet) we mentioned a paper from Richard von Noorden, who was writing in Nature. You can see the paper here.
The paper is well worth a read, and we would encourage you to do so but, but here are the main points that we took away.
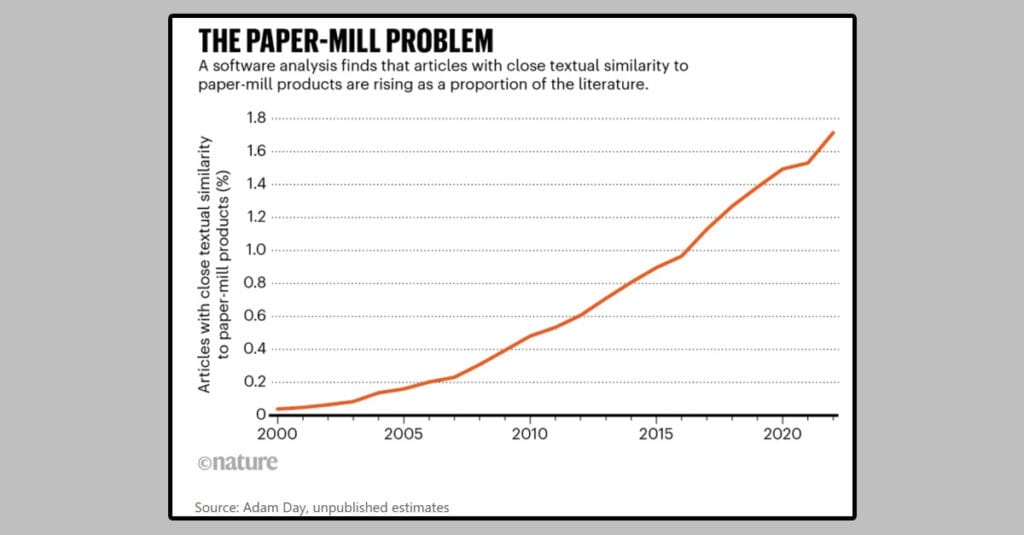
- Over the past two decades, more than 400,000 research articles have been published that show strong textual similarities to known studies produced by paper mills. Around 70,000 of these papers were published last year (2022). It is estimated that 1.5–2% of all 2022 scientific papers could be from paper mills.
- ClearSkiesAdam says that it is impossible to know whether all of the papers he identified are from paper mills but the few percent is a reasonable, conservative estimate.
- MicrobiomDigest says that ClearSkiesAdam‘s estimate, ‘although staggeringly high, is not impossible‘, adding that it would be useful to see the full details of Day’s methods and examples.
- JAByrneSci says ‘Sadly, I find these estimates to be plausible‘.
- Day (ClearSkiesAdam) believes that his estimate is a lower bound, as his method will miss paper mills that avoid known templates. Paper mills target particular titles, rather than there being an even distribution across all journals. Day does not reveal the publishers which appear to be the most affected.
- In June 2022, C0PE (Committee on Publication Ethics) said that 2% of submitted papers could come from papers mills for most journals and could be as high as 40% for some journals.
- Bernhard Sabel posted a preprint in May 2023 suggesting that a paper with an author who is affiliated with a hospital, and gives a non-academic email address, should be flagged as a paper that could be from a paper mill. Sabel estimates that 20–30% of 2020 papers in medicine and neuroscience were possibly from paper mills, later reducing this estimate to 11%. He acknowledges that his method would flag false positives.
- Retraction Watch records fewer than 3,000 retractions related to paper mills, out of the 44,000 papers that it has retracted.
- ivanoransky (co-founder of Retraction Watch) says the figure would be higher as some publishers avoid the term ‘paper mill’ when explaining the reason for retraction.
Whatever you take away from this article as the important points, the key takeaway is that paper mills are a very big concern and are undermining the integrity of the scientific archive (there is a strong argument that the damage has already been done).
We let Day have the final word. The final part of the article reads:
Those retraction numbers are “only a small fraction of the lowest estimates we have for the scale of the problem at this stage”, says Day. “Paper-mill producers must feel pretty safe.”
You can see our tweet, on which this article is based here.

