Unless you have been living on Mars, you cannot have avoided the discussion over ChatGPT (and other large language models) that has been going on for the past few months.
The discussion is not only about the uses that ChaptGPT can be put to, but also how content generated with these type of tools can be identified, which is important in the context of scientific publishing.
In this article, we look at a journal which has published a paper generated by ChatGPT. We have to say, that this is an obvious example, due to the naivety of the author and the lack of peer review. But this should only serve as a warning that journals/authors are already publishing papers written by large language models and they will not all be so easy to spot.
Are we allowed to used ChatGPT?
The short answer is no, or at least AI tools do not meet the conditions to be an author on a paper. This is stated by many organizations, such as COPE (Committee on Publication Ethics), which says:
“AI tools cannot meet the requirements for authorship as they cannot take responsibility for the submitted work. As non-legal entities, they cannot assert the presence or absence of conflicts of interest nor manage copyright and license agreements.” [See here]
The same COPE web page goes on to say:
“Authors who use AI tools in the writing of a manuscript, production of images or graphical elements of the paper, or in the collection and analysis of data, must be transparent in disclosing in the Materials and Methods (or similar section) of the paper how the AI tool was used and which tool was used. Authors are fully responsible for the content of their manuscript, even those parts produced by an AI tool, and are thus liable for any breach of publication ethics.“
Many other publishers and organizations have also come out with similar statements.
How can you spot a ChatGPT paper?
There is a lot of work being done on how to detect AI written papers. One of the world’s leading plagiarism detectors (Turnitin) is looking to upgrade its tool to spot AI generated content.
This is to be welcomed, although it is likely to lead to an arms race where there is as much work being done how to avoid detection by tools such as Turnitin, as there is on developing the tools to detect this sort of content. You only need to do a search on how to avoid plagiarism detectors to show that this has been going on for many years.
However, there are times when we do not need these tools, you just need to look at the paper itself and apply some common sense.
But, first, let’s take a look at a specific journal.
The journal is an established journal, first being published in 1996.
Google Scholar
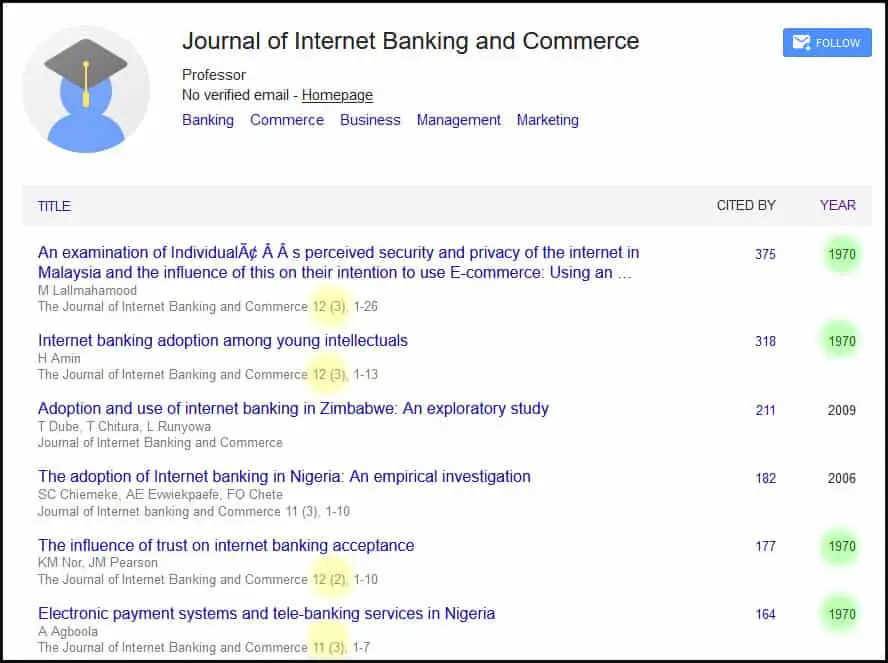
If you look at the journal’s Google Scholar page, there are articles going back to 1970 (see Figure 1). We note though that the papers marked as 1970, have volume numbers as 12 and 13, which are from 2006 and 2007 and those papers do appear in those years, so it looks like a Google Scholar metadata issue.
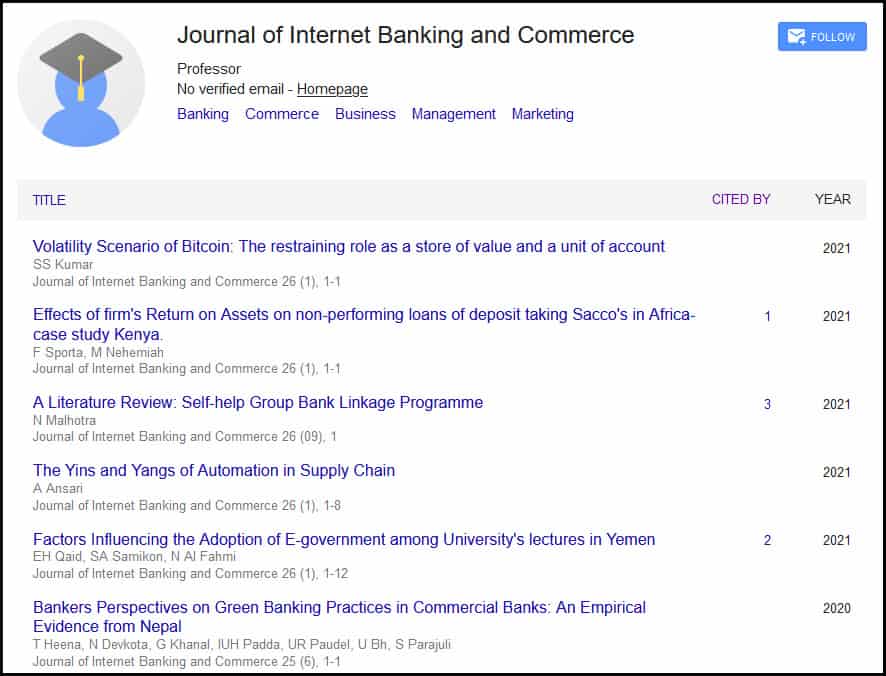
We also note that there are no papers on their Google Scholar profile beyond 2021 (see Figure 2).
Figure 1: Google Scholar page for the Journal of Internet Banking and Commerce showing that some papers date back to 1970, even though it did not start publishing until 1996
Figure 2: Google Scholar page for the Journal of Internet Banking and Commerce showing that no papers are indexed after 2021
Indexing in Scopus
The Journal of Internet Banking and Commerce was indexed in Scopus from 2009 to 2016, but was then discontinued (see Figure 3).
Figure 3: Journal of Internet Banking and Commerce: Scopus Coverage
Article Processing Fees
The Article Processing Fees (APC) for the Journal of Internet Banking and Commerce is USD 2,019 and the journal also participates in the Fast Editorial Execution and Review Process. For an extra USD 99 (payable at submission time) it provides a review in 3-5 days and publication two days after.
We mention in passing, as this always frustrates us, that the journal says (see archived page here) that:
“Articles published in Journal of Internet Banking and Commerce have been cited by esteemed scholars and scientists all around the world. Journal of Internet Banking and Commerce has got h-index 35, which means every article in Journal of Internet Banking and Commerce has got 35 average citations.“
This is just the wrong definition of h-index.
The Article
The article that we are interested in, is titled “Stock Price Prediction based on Gradient Descent using a Back Propagation Neutral Network“. The citation is:
Selvamuthu D. (2023) Stock price prediction based on gradient descent using a back propagation neutral network. Journal of Internet Banking and Commerce 28(1).
You can access the article here. We have also archived the web page here. The PDF, as well as being available via the journal’s web site, is also available here.
Figure 4: Screenshot of the journal article, highlighting that it was generated with ChatGPT (or similar)
Figure 4 shows a screen shot of the article. The part we draw your attention to is the text highlighted in yellow, which says:
“As an AI language model, I can give you some information …“
It is obvious that this text has been generated by ChatGPT (or some other language model). Looking at the rest of the paper we would guess that the entire paper has been generated by ChatGPT (or similar).
Our Comments/Thoughts
We have the following comments about this journal/paper.
The paper cannot have undergone any peer review. Surely, any cursory read (by a reviewer, for example) would have highlighted the fact that the paper had been written by ChatGPT (or similar).
This area (Artificial Neural Networks – ANN) is something we know a little about (otherwise we would not comment on the technical content of the paper). This paper is very naive and could have been written in the 1980’s when interest in ANN started to gain traction. Even though, the paper is really nothing more than a general introduction to ANN’s. There is certainly nothing that is reproducible.
The references are all quite old, with only one from 2021.
If the author, their institution or another stakeholder paid over USD 2,000 to have this published then they wasted their own money or, perhaps more likely, wasted the money of the tax payers. Of course, the journal will be very happy to have received this money. We can’t help feel though that the money could have been used for much better things.
Finally
If the journal, publisher or author feel that we are wrong in our analysis, or are being unfair, then we would be delighted to enter into a conversation and withdraw or update this article as a (possible) outcome.
Acknowledgements
We were motivated to write this article after seeing a LinkedIn post by Matt Hodgkinson. You can see the post here (assuming you have access to LinkedIn). Matt’s post not only features the paper we mention above but also has other examples which, if not so worrying, would be funny.