
Ten Challenges that Threaten the Integrity of Scholarly Publishing
Introduction Scholarly publishing is one of the cornerstones of our global knowledge base. It enables the free exchange of ideas, […]
Introduction Scholarly publishing is one of the cornerstones of our global knowledge base. It enables the free exchange of ideas, […]

A DOI is a permalink to a scientific paper. It says nothing about the quality of a publisher, a journal or a paper. In this article we look at what a DOI is and what it means for predatory publishing.

We ask why somebody would publish more than one letter a day in scientific journals and what workflow this would entail.
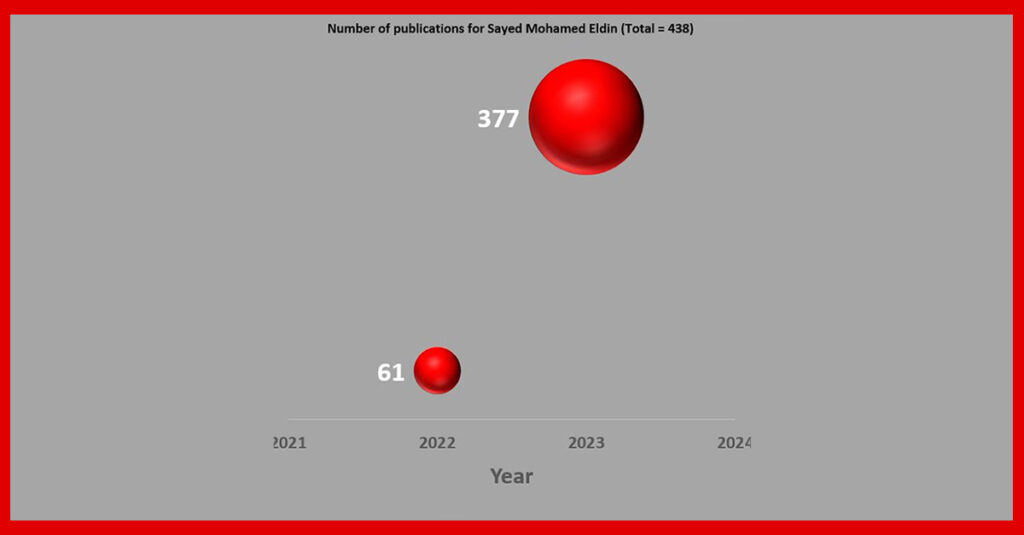
We look at the number of papers published by Sayed Mohamed Eldin published in 2022-2024. Prior to 2022, we cannot find any publications.
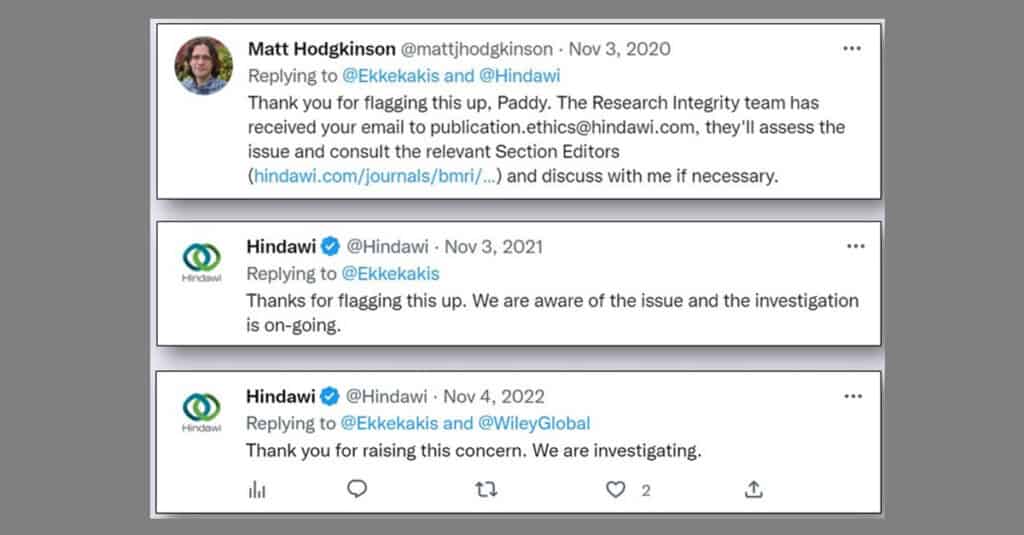
Ethical concerns were raised about three years ago, saying that a paper contained fake meta-analysis. The publisher says that it is still under investigation. We give our thoughts.
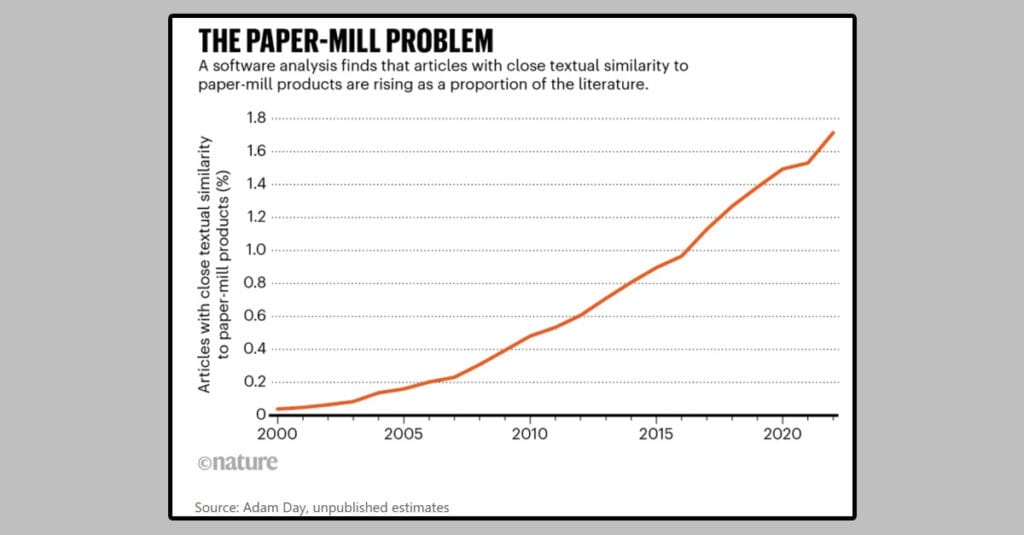
A recent Nature paper presented the issue of paper mills. We gives out take home messages from this paper.

Elsevier carried out a “stealth change” to a published paper. We look at the details.
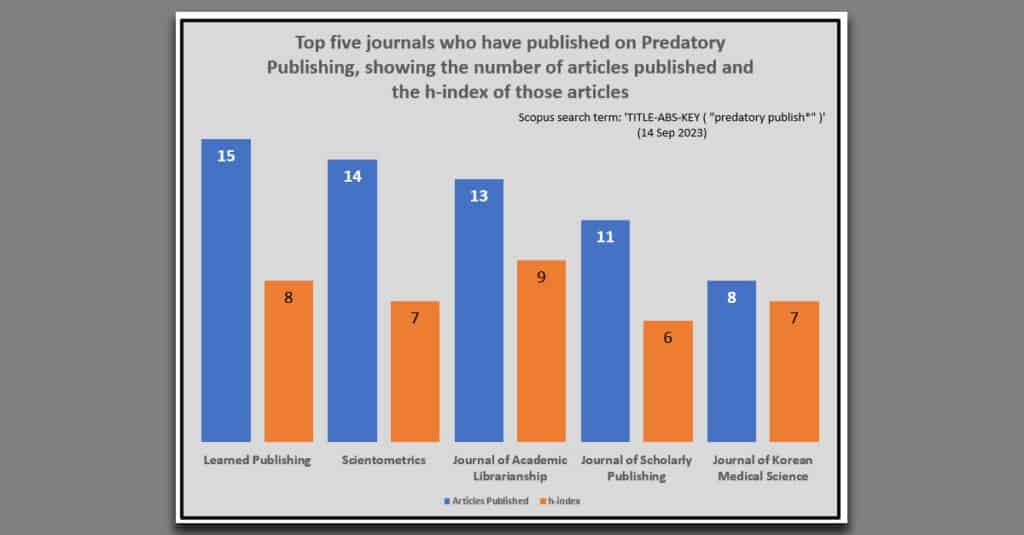
We list the journals that have published the most papers on predatory publishing, along with the h-index of those articles

We highlight two recent papers that address the topic of detecting AI generated text
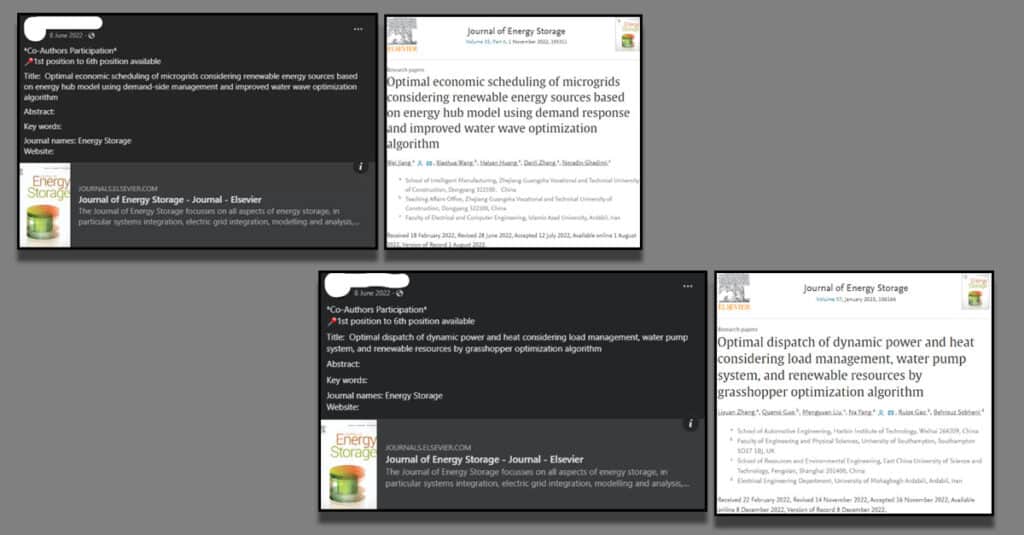
We respectfully ask Elsevier to investigate two papers that appear to have been published after authors have paid to be an author.