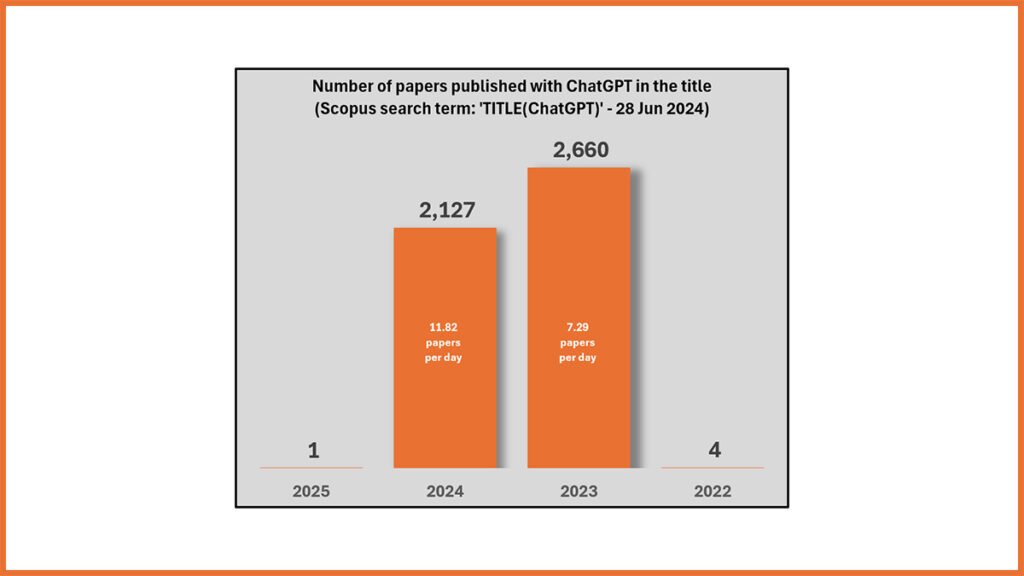
Eleven papers are published every day with ChatGPT in the title
We have looked at how many papers with ChatGPT in the title. In 2024, more than 11 papers have been published every day.
We have looked at how many papers with ChatGPT in the title. In 2024, more than 11 papers have been published every day.

Most journals require authors to acknowledge the use of Large Language Models, as as ChatGPT. We are argue that this does not go far enough.

We look at a paper that was generated with ChaGPT and ask can anybody now write a scientific paper?

Some journals now allow ChatGPT-authored text to be used in articles. We express some of our views

We highlight two recent papers that address the topic of detecting AI generated text
As at 22 Aug 2023 985 papers have been published with ChatGPT in the title.

We asked ChatGPT how you can identify a predatory journal. Here is what it said.

In our opinion, if you ChatGPT to help with the writing of your paper, you must acknowledge its use.

Generators, such as ChapGPT, cannot be listed as authors on a paper, yet this is happening and (in some cases) it is easy to spot.

A recent Twitter survey asked for people’s views of Frontier Media. We discuss this survey and also ask ChatGPT for its thoughts.